
Volltextdigitalisierung: Methoden und Werkzeuge
(Autorin: Ursula Schultze, 30.09.2015)
Bevor man ein Wörterbuch digitalisiert, muss man sich darüber im Klaren sein, wie genau das Digitalisat im Anschluss aussehen soll, welche Anforderungen an die Darstellung gestellt werden und für welche Zwecke das Wörterbuch später verwendet werden soll bzw. welche Ziele mit der Digitalisierung verfolgt werden: Möchte man zum Beispiel ein Wörterbuch nur digital nachbilden oder soll man zudem die Lemmaliste oder sogar ganze Volltexte durchsuchen können? Zuerst muss eine genaue linguistische Analyse der Artikel vorgenommen werden. Hierbei werden die Struktur und der Inhalt detailliert untersucht. Sobald man dies gemacht hat, kann man entscheiden, welche Verfahren für das Digitalisierungsvorhaben die besten Ergebnisse liefern. Nachdem die gewünschten Anforderungen definiert worden sind, wird das Wörterbuch eingescannt, so dass alle Seiten in Bilddateien vorliegen. Nun stellt sich die Frage: Wie werden diese Bilder in Texte umgewandelt, um sie weiter bearbeiten und mit Informationen anreichern zu können? Dafür gibt es verschiedenen Methoden und Werkzeuge. Im Folgenden werden drei Möglichkeiten vorgestellt:
OCR
OCR steht für Optical Character Recognition. Mit OCR ist es möglich, Text in Bildern automatisiert zu erkennen. Für diese Methode der Texterkennung gibt es verschiedene Programme:
- ABBYY FineReader: ABBYY ist ein russischer Softwarehersteller, der Anwendungen des maschinellen Sehens entwickelt. Der FineReader ist eine Software zur Texterkennung, welche die Konvertierung von Scans in durchsuchbare PDFs ermöglicht.
- Omnipage: Ominpage ist eine Software, die Textvorlagen in Textdokumente umsetzt. Ominpage erkennt 56 Sprachen, darüber hinaus verfügt die Software über eigene Wörterbücher für die 19 häufigsten Sprachen.
- Tesseract: Tesseract ist eine Software zur Texterkennung. Es ist ein reines Zeichenerkennungsprogramm, das ohne statistische Modelle arbeitet und keine graphische Benutzeroberfläche bietet. Tesseract ist eine quelloffene Software, was bedeutet, dass jeder die Software nutzen, kopieren und verändern darf.
- OCRopus: OCRopus ist eine Software zur Dokumentanalyse und Texterkennung. Sie nutzt statistische Sprachmodelle und ist genauso wie Tesseract quelloffen.
Damit ein Programm den Text in einem Bild erkennen kann, ist es wichtig, dass die Qualität der Scans den Anforderungen der Software und den Gegebenheiten der Vorlage angepasst wird. Je besser die Qualität eines Scans ist, umso zuverlässiger funktioniert auch die Texterkennung des Programms. Hinter OCR-Programmen stehen komplexe technische Prozesse, den Arbeitsablauf kann man sich aber recht einfach vorstellen. Zuerst erfolgt die Bildverarbeitung. Hierbei werden die Bildkontraste verstärkt und es folgt die sogenannte Binarisierung. Mit der Binarisierung regelt man die Helligkeit des Bildes, d.h. ab welchem Grauwert eine Stelle schwarz oder weiß dargestellt werden soll. Nachdem das Bild bearbeitet wurde, erfolgt die Layout-Analyse, das Bild wird erst in Textblöcke eingeteilt, dann wird nach Linien segmentiert. Dies kann man sich so vorstellen, dass unter jeder Textzeile eine Linie gezogen wird, wodurch das Programm den Zeilenverlauf erkennt. Nachdem der Textverlauf mit Linien versehen worden ist, wird nach Wörtern segmentiert. Das Programm berechnet hierbei, wo ein Wort anfängt und endet. Dann werden die Wörter in einzelne Buchstaben segmentiert und im Anschluss wird der Buchstabe selbst rekonstruiert, dies wird als Charakterklassifikation bezeichnet. Viele OCR-Programme arbeiten zudem mit statistischen Sprachmodellen, zum Beispiel mit N-Grammen, die eine Wahrscheinlichkeitsberechung von Buchstabenfolgen ermöglichen. Aber man sollte nicht vergessen, dass man mit einem Programm arbeitet. Programme arbeiten zwar oft genauer und effizienter als Menschen, dennoch machen sie auch Fehler, da sie mit Ausnahmen, sofern diese nicht implementiert wurden, nicht umgehen können. Daher ist nach dem Durchlauf der OCR-Software eine Nachkorrektur unerlässlich. Diese kann automatisch oder händisch erfolgen. Auch sollte bei großen Texterkennungsaufgaben in jedem Fall eine Ergebnisevaluation zu Anfang erfolgen, damit man im Falle zu vieler Fehler andere Einstellungen des Programms oder eine Änderung der Scanqualität vornehmen kann, um damit die Fehlerrate zu senken. Dies erspart später wiederum Arbeit und Zeit und vor allem Forschungsgelder. Der Output einer OCR-Software kann in verschiedenen Formaten erfolgen: PDF, DOCX, RTF oder HTML oder als XML. OCR eignet sich besonders für moderne und im besten Fall maschinengeschriebene Textdokumente, da hier ein deutliches Druckbild und ein guter Kontrast gegeben sind.
Hier soll an einem Beispiel gezeigt werden, wie eine OCR-Software arbeitet und vor welchen Herausforderungen man stehen kann:
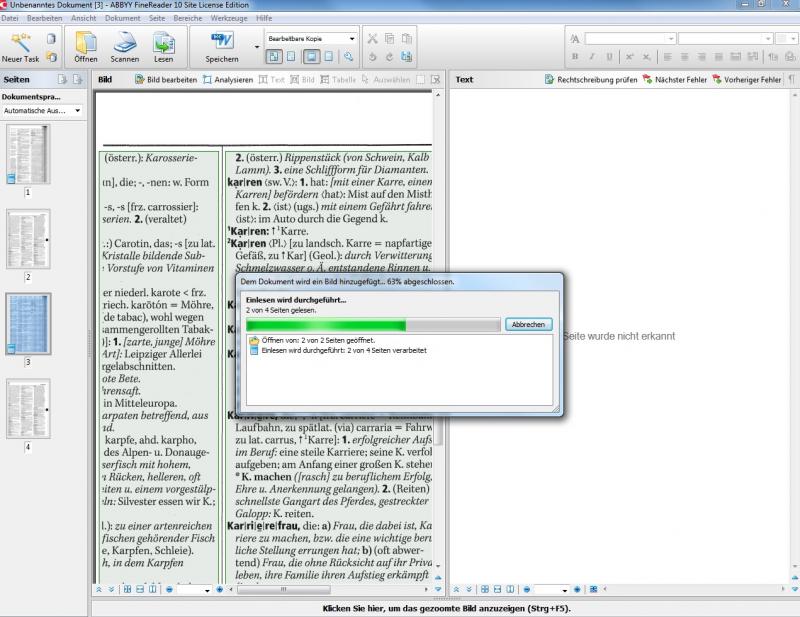
Diese Ansicht erhält man, wenn man ein PDF- Dokument als Scanergebnis einlesen lässt. Das Programm geht Seite für Seite durch. Im Hintergrund wird zudem die Sprache des Dokuments geprüft.In unserem Fall ist dies Deutsch, da wir einen Scan aus dem Duden Universalwörterbuch von 2006 eingelesen haben. ABBYY FineReader 10 ist hier die verwendete OCR-Software. Als vorteilhaft erweist sich, dass man die Dokumentsprache auch selbst einstellen kann. So kann ABBYY FineReader zum Beispiel auch einen Text erkennen, der in asiatischen Schriftzeichen abgefasst ist.
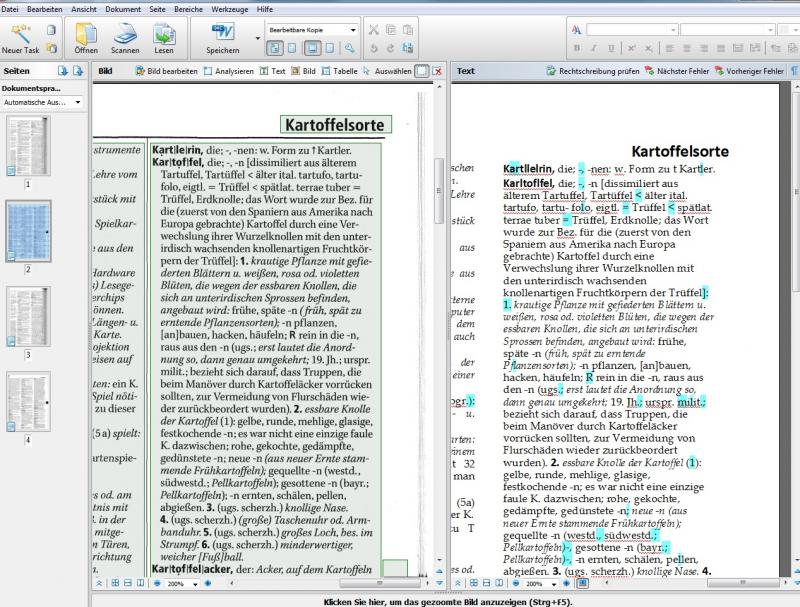
Nach dem Einlesen findet man diese Ansicht auf dem Bildschirm wieder. Auf der linken Seite sehen wir das Original, dessen Text in Kästen eingeteilt wurde, in denen das Programm die Seite in Schriftblöcke untergliedert. Innerhalb dieser Blöcke befindet sich der Text, der erkannt wurde. Auf der rechten Seite befindet sich das Ergebnis der OCR-Software. Das Programm hat alle Buchstaben erkannt, lediglich die Formatierung wurde zum Teil nicht beibehalten. Die blau markierten Buchstaben und Ziffern stellen Zweifelsfälle dar, bei denen die Software nicht sicher entscheiden konnte, ob diese Zeichen richtig erkannt wurden und den deutschen Rechtschreibregeln entsprechen.
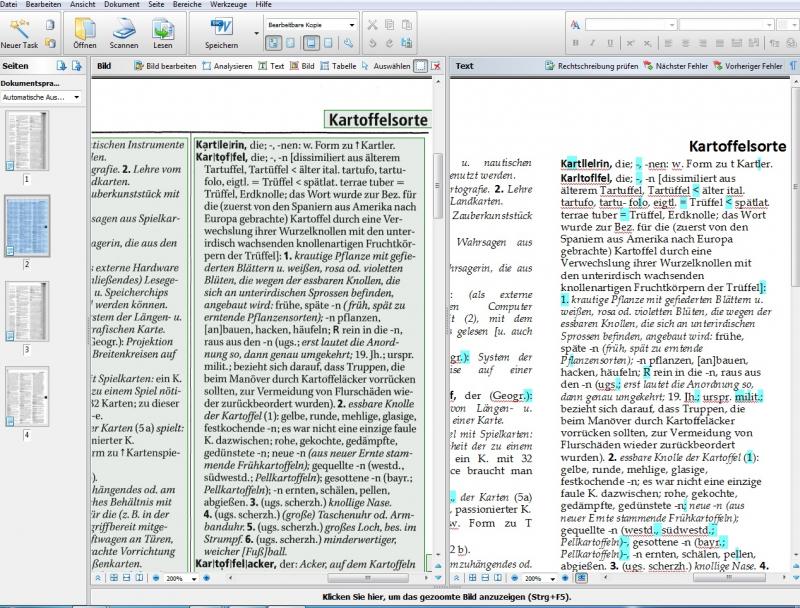
Wirft man einen konkreten Blick in das Wörterbuch und schaut sich Struktur und Inhalt an, erkennt man, dass die OCR-Software an dieser Stelle schon einiges leisten kann. Die Einteilung des Textes in Blöcke erweist sich als vorteilhaft, da hiermit sehr gut die Textstruktur von Wörterbüchern erfasst werden kann. Viele Wörterbücher zeichnen sich nämlich dadurch aus, dass sie über einen Spaltensatz und -druck verfügen. Dies wird gut umgesetzt von der OCR-Software.
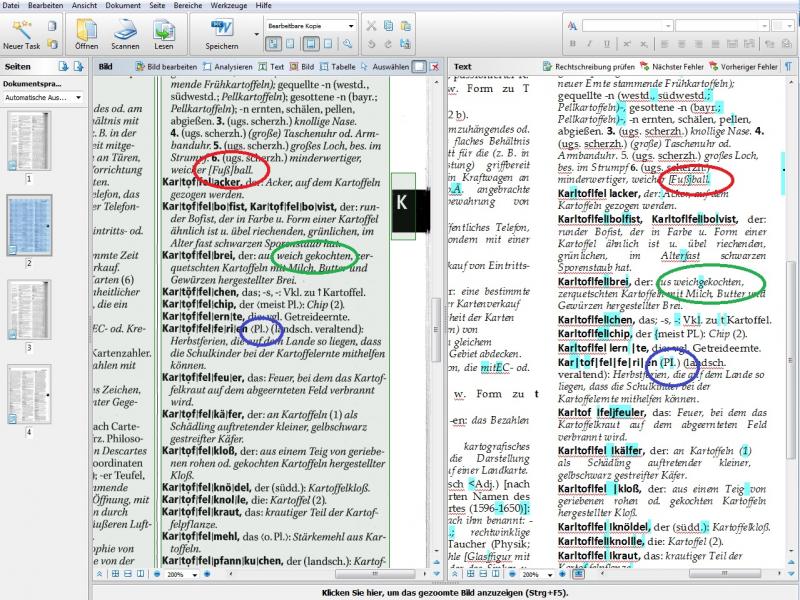
In diesem Bild ist zu sehen, ab wann die OCR-Software an ihre Grenzen stößt. Sonderzeichen, aber auch Leerzeichen (hier rot, grün und blau eingekreist) werden nicht erkannt und fälschlich als Buchstabe (roter Kreis rechts) oder gar nicht (grüner Kreis links) wiedergegeben. Gleiches kann aber auch bei den spitzen Klammern passieren, dazu vergleiche man die blauen Kreise auf der rechten und linken Seite im Bild. Trotz solcher Fehler erweist sich eine OCR-Software jedoch in den meisten Fällen gerade bei modernen, maschinengeschriebenen Textdokumenten als ein hilfreiches und zeitsparendes Werkzeug im Vergleich zum händischen Abtippen eines Textes.
Double Keying
Double Keying bezeichnet eine Methode des händischen Abschreibens von gedruckten oder handschriftlichen Vorlagen. Diese Methode eignet sich besonders, wenn der Druck eines Wörterbuchs verwischt, undeutlich oder sehr eng gesetzt ist, oder das Wörterbuch viele Sonderzeichen, wechselnde Schriftarten und Schriftgrößen beinhaltet. Eine OCR-Software würde hier an Grenzen stoßen und fehlerhaften Output produzieren. Für das Double Keying-Verfahren werden die Wörterbuchartikel vorstrukturiert und eine Layoutanalyse vorgenommen. Die Strukturierung sowie die Analyse werden dann an eine Firma geschickt, die Double Keying-Dienste anbietet. Vorteilhaft dabei ist, wenn Nicht-Muttersprachler die Vorlage abschreiben, da Muttersprachler oftmals unbewusste Fehlerkorrekturen vornehmen und es gerade bei Sonderzeichen wichtig ist, dass diese originalgetreu abgebildet werden. Oftmals werden daher die Dienste von Firmen aus dem asiatischen Raum in Anspruch genommen. Beim Double Keying wird zweimal abgeschrieben, dies hat den einfachen Grund, dass, wenn Fehler gemacht werden, die Wahrscheinlichkeit sehr gering ist, dass diese an ein und derselben Stelle zweimal erfolgen. Gleichzeitig werden auch Informationen über Schriftschnitte, Schriftgrößen und sonstige Layoutmerkmale mit ausgezeichnet, was die spätere Verarbeitung erheblich erleichtert. Nachdem die abgeschriebenen Versionen vorliegen, werden diese miteinander verglichen. In der Regel erfolgt dies erst automatisch und wird danach händisch korrigiert. Wichtig ist, wenn sich bei der Digitalisierung für das Double Keying entschieden wird, dass genaue Vorgaben darüber gemacht werden, was genau wie abgeschrieben werden soll: Zum Beispiel, wie sieht ein Eigenname aus (ist er zum Beispiel kursiv gedruckt), wo beginnt und wo endet er und welche Elemente kann der Name beinhalten. Gleiches gilt auch bei anderen Angaben, z.B. Adressen, Belegstellen, grammatischen Angaben usw. sowie bei den verschiedenen Möglichkeiten, wie ein Name geschrieben werden kann und was Namensangaben beinhalten können.
Ein Beispiel für die verschiedenen Möglichkeiten, Namen anzugeben:
- Peter Müller
- Müller, Peter
- P. Müller
- Müller, P.
- P. Müller und F. Meier
- Müller, P./ Meier, F.
- Peter Müller et al.
Gibt es trotz genauer Vorgaben, was wie erfasst werden soll, dennoch Zweifelsfälle, werden diese genau dokumentiert, dem Auftraggeber übersandt und dieser schickt wiederum eine Lösung für solche Fälle an die Firma zurück.
Handwritten Text Recognition (HTR)
Liegt das Wörterbuch als handschriftliches Dokument vor, so wie es bei vielen sehr alten Wörterbüchern oder Glossen (eine Vorform der Wörterbücher) der Fall ist, bietet es sich an, neben Double Keying-Verfahren durch wissenschaftliches Personal mit Methoden der Handwritten Text Recognition (kurz: HTR) zu arbeiten. Hierfür gibt es einige Tools:
- Transkribus
- Transkriptorium
- T-PEN
- Transkript
- Virtual Transcription Laboratory
- weitere verschiedene Tools zur Digiatlisierung von Texten
HTR-Tools arbeiten mit Algorithmen des Maschinellen Lernens. So greifen sie beispielsweise auf künstliche neuronale Netze, Hidden Markov Modelle und N-Gramme zurück. Künstliche neuronale Netze kann man sich in Analogie zu biologischen neuronalen Netzen vorstellen. Sie bestehen aus mehreren Schichten. Es gibt eine Eingangsschicht, in welche die Daten von der Außenwelt hinein kommen, beispielsweise ein Bild. Die Erkennung des Bildes beziehungsweise die Erkennung von Text in einem Bild erfolgt in mehreren Zwischenschichten, in denen das Programm das Bild oder den Text schrittweise erkennen kann. So wird beispielsweise in einer ersten Schicht die Pixelzahl festgestellt. In einer weiteren Schicht erkennt das Programm, dass verschiedene Pixel verbunden sind, es werden Kanten rekonstruiert. In einem nächsten Schritt können beispielsweise Konturen ausgemacht werden, bis das Bild vollständig berechnet und konstruiert werden kann, so dass das System beispielsweise erkennen kann, wo ein Buchstabe steht und wie er aussieht. Zum Schluss gibt es eine Ausgangsschicht, welche die intern verarbeiteten Daten wieder an die Außenwelt und somit an den Programmnutzer abgibt. Vorteil bei Algorithmen des Maschinellen Lernens ist, dass man sie trainieren kann. Das heißt, man gibt dem System eine Menge von Beispielen und das System lernt anhand dieser Beispiele. Ob das Richtige gelernt wird, kann kontrolliert werden, indem man Testdaten verwendet und einen Gold-Standard definiert. Je komplexer ein System jedoch ist, umso schwieriger gestaltet sich die Lernkontrolle. Zudem stellt die automatische Handschriftenerkennung bis heute einen Bereich der Forschung dar, der noch große Potentiale birgt. So beläuft sich die Exaktheit bei der automatischen Handschriftenerkennung bisher auf höchstens 40 Prozent, was bedeutet, dass rund drei Fünftel der Ergebnisse falsch sind. Die Segmentierung von einzelnen Wörtern kann nach Abschluß der Erkennung mithilfe von N-Grammen und Hidden Markov Modellen berechnet werden. Mit N-Grammen können Texte segmentiert und in Fragmente zerlegt werden. Fragmente können einzelne Buchstaben, Buchstabensequenzen, Phoneme oder Wörter sein. Es wird dann berechnet, mit welcher Wahrscheinlichkeit ein Fragment auf ein anderes folgen könnte.
Hidden Markov Modelle sind stochastische Verfahren zur Mustererkennung, mit denen Prognosen über einen Prozess getroffen werden können, der aus Zuständen und Ereignissen besteht, wobei die Zustände versteckt sind. Für die Texterkennung sind Hidden Markov Modelle interessant, da mit ihnen berechnet werden kann, ob ein Buchstabe richtig erkannt werden kann. Dazu wird das aktuelle Zeichen und ein hinterlegtes Wörterbuch verwendet. Es wird nun errechnet, mit welcher Wahrscheinlichkeit dieses Zeichen in Abhängigkeit des vorhergehenden Zeichens und dessen, was im Wörterbuch hinterlegt ist, richtig erkannt wird.
In der Praxis sieht das folgendermaßen aus: Das Tool Transkribus beispielsweise stellt ein Werkzeug dar, das mit HTR-Methoden arbeitet. Hier kann man den Scan eines Buches hineinladen, der vorher mit einer OCR-Software bearbeitet wurde. Diese Vorverarbeitung ist notwendig, um den Scan bzw. das Bild mit Bildvektoren zu versehen, mit denen dann verschiedene Berechnungen durchgeführt werden können. Das Programm erkennt die Umrisse von handschriftlichen Zeilen und es ermittelt eine Grundlinie.
Um nun dem Programm implementieren zu können, was auf einer Seite steht, hat man die Möglichkeit, in einem Textfeld den Text einzugeben, der auf dem Manuskript geschrieben steht. Dazu muss man die Umrisse der handschriftlichen Zeilen anklicken, die dann bunt eingefärbt werden.
Nun gibt man den entsprechenden Text ein. Um das Programm so trainieren zu können, dass es eigenständig die Handschrift erkennen kann, sollte man rund 100 Seiten transkribiert haben, damit eine ausreichende Beispielmenge vorliegt. Diese Transkription gibt man dann an die Entwickler weiter, so dass diese das Programm speziell für diesen Text trainieren können. Auch hier sollte man sich bewusst sein, dass Computerprogramme zwar hilfreich, letztlich aber auch fehleranfällig sind, da sie immer nur das machen können, was man ihnen zuvor implementiert hat. Daher ist hier eine nachträgliche händische Korrektur unerlässlich.
Ball, Rafael, Volltextdigitalisierung, online: http://www.digitalisierung.ethz.ch/volltextdigitalisierung.html [16.07.2015].
Ball, Rafael, Best Practices Digitalisierung, online: http://www.digitalisierung.ethz.ch/index.html [16.07.2015].
Burch, Thomas; Gärtner, Kurt, Standards der Volltextdigitalisierung am Beispiel der Mittelhochdeutschen Wörterbücher auf CD-ROM und im Internet, 2000, online: http://www.muenchener-digitalisierungszentrum.de/content/veranstaltung/2000-11-28/burch.html [16.07.2015].
Cash, Glenn; Hatamian, Mehdi, Optical Character Recognition by the Method of Moments, in: Computer Vision, Graphics, and Image Processing, Jg. 39, Bd. 3/ 1987, S. 291-310, online: http://www.sciencedirect.com/science/article/pii/S0734189X87801834 [16.07.2015].
Cox, Anna; Oladimeji, Patrick; Thimbleby, Harold, Number Entry Interfaces and Their Effects on Error Detection, in: Human Computer Interaction - INTERACT 2011, 13th IFIP TC 13 International Conference, Lisbon, Portugal, September 5-9, 2011, Proceedings, Part IV, online: http://www.cs.swansea.ac.uk/~csharold/cv/files/interact2011.pdf [16.07.2015].
Deutsche Forschungsgemeinschaft, DFG-Praxisregeln »Digitaliserung (02/2013)«, online: http://www.dfg.de/formulare/12_151/12_151_de.pdf [15.07.2015].
Eikvil, Line, OCR - Optical Character Recognition, Oslo 1993, online: https://www.nr.no/~eikvil/OCR.pdf [16.07.2015].
Geyken, Alexander; Haaf, Susanne; Wiegand, Frank, Measuring the Correctness of Double-Keying. Error Classification and Quality Control in a Large Corpus of TEI-Annotated Historical Text, Journal of the Text Encoding Initiative, Nr. 4, März 2013, online: https://jtei.revues.org/739 [16.07.2015].
Kompetenzzentrum für elektronische Erschließungs- und Publikationsverfahren in den Geisteswissenschaften
Universität Trier, Volltextdigitalisierung, online: http://kompetenzzentrum.uni-trier.de/de/schwerpunkte/volltextdigitalisierung/ [15.07.2015].
Kompetenzzentrum für elektronische Erschließungs- und Publikationsverfahren in den Geisteswissenschaften
Universität Trier, DWB Volltextdigitalisierung, online: http://dwb.uni-trier.de/de/die-digitale-version/volltextdigitalisierung/ [16.07.2015].
Max-Planck-Gesellschaft zur Förderung der Wissenschaften e.V., Volltexte, online: https://dlcproject.wordpress.com/tag/texterfassung/ [16.07.2015].
Thaller, Manfred, Was heißt und zu welchem Ende betreiben wir Volltextdigitaliserung?, Vortragsfolien 2011 [16.07.2015].
Unterausschuss für Kulturelle Überlieferungen im Bibliotheksausschuss der Deutschen Forschungsgemeinschaft, Die Erschließung und Bereitstellung digitalisierter Drucke, online: http://forge.fh-potsdam.de/~ABD/wa/Digitale_Edition/Dokumente/DFG_Konzept_digitale_drucke.pdf [15.07.2015].
Wegstein, Werner; Blümm, Mirjam; Seipel Dietmar; Schneiker, Christian, Digitalisierung von Primärquellen für die TextGrid-Umgebung: Modellfall Campe-WB, online: http://www.textgrid.de/fileadmin/berichte-1/report-4-1.pdf [15.07.2015].