
Warum automatisierte Handschriftenuntersuchung?
(Autorin: Ruth Bruchertseifer, 15.05.2016)
Immer mehr Bibliotheken digitalisieren ihre mittelalterlichen Handschriften, sodass diese in steigender Anzahl in digitalen Bibliotheken online zur Verfügung stehen. Dadurch eröffnen sich neue Möglichkeiten bei deren Erforschung. Denn Handschriften können zwar ausführlich und für sich genommen betrachtet werden, aber ebenso kann man sie auf Zusammenhänge mit einer großen Zahl anderer Handschriften untersuchen.
Der große Nachteil einer solchen quantitativen Analyse analoger Bestände ist der hohe Zeitaufwand. Denn die Ausprägungen der Merkmale, anhand derer Vergleiche zwischen den Schriften vorgenommen werden können, müssen für jede Handschrift einzeln ermittelt werden. Deshalb stößt man zeitlich schnell an Grenzen, wenn große Mengen an Handschriften betrachtet werden sollen. Liegen die Handschriften jedoch digitalisiert vor, wird ihre Untersuchung in wesentlich höherer Anzahl möglich, sofern man die benötigten Daten automatisiert durch Software erheben lässt. Eine solche automatisierte Untersuchung bildet auch die Grundlage für das Projekt eCodicology.
Was soll untersucht werden?
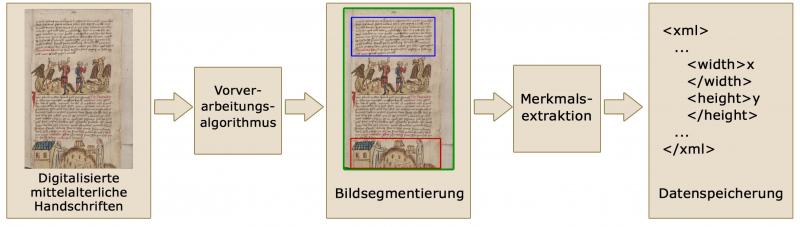
Ablauf des Bildverarbeitungsprozesses für digitalisierte Handschriften (Graphik: Swati Chandna, CC BY-SA 4.0).
Damit eine Software brauchbare Ergebnisse erzielen kann, gilt es zu beachten, dass jedes Computerprogramm letztendlich nur aus Abfolgen von Befehlen besteht. Eine solche Folge von eindeutigen Anweisungen, die außerdem so formuliert sind, dass sie sich auf eine ganze Gruppe gleichartiger Probleme anwenden lassen, wird Algorithmus genannt. Ein oder mehrere dieser Algorithmen, die für den Computer verständlich in einer Programmiersprache niedergeschrieben wurden, bezeichnet man als Programm.
Diese Funktionsweise von Computerprogrammen hat Auswirkungen auf das Vorgehen bei der automatisierten Handschriftenanalyse. Vor der Analyse wird zunächst von den Wissenschaftlern entschieden, welche Merkmale der Handschriften für Untersuchungen von Bedeutung sein könnten. Dieser Schritt erfolgt sowohl bei händischer als auch bei automatisierter Herangehensweise. Sollen die ausgewählten Merkmale jedoch durch Software ermittelt werden, muss man als nächstes einen Kompromiss finden zwischen den denkbaren und den in der Praxis tatsächlich feststellbaren Merkmalen. Denn nicht jedes wissenschaftlich relevante Merkmal kann zum jetzigen Stand der Technik auch automatisch erkannt werden. Die oftmals besonders verzierten Anfangsbuchstaben (Initialen) auf einer Handschriftenseite können beispielsweise noch nicht einwandfrei als eine eigene Kategorie im Vergleich zu Bild- und Textbereichen abgegrenzt werden. Das gleiche Problem gilt bei Randbemerkungen, die an den eigentlichen Text angefügt wurden und oftmals eine komplette eigene Untersuchung erfordern würden, von einem Algorithmus allerdings nicht vom Haupttext unterschieden werden können.
Für das Projekt eCodicology wurden nach solchen Überlegungen die Größen der verschiedenen Seiteneinheiten als zu betrachtende Merkmale ausgewählt: die Seitengröße selbst, aber auch die Maße der beschriebenen Fläche auf einer Seite, die Größe der Bilder, sofern vorhanden, und die Zeilenhöhe. Die Handschriften, die im Projekt eCodicology auf ihre Ausprägungen der zuvor genannten Merkmale untersucht werden, stammen aus dem Projekt Virtuelles Skriptorium Sankt Matthias.
Welche Software wird im Projekt eCodicology verwendet?
Sind geeignete Merkmale festgelegt worden, können die Algorithmen für die Untersuchung entwickelt werden. Vielfach sind die Anforderungen an eine Anwendung allerdings so komplex, dass es sehr zeitaufwändig wäre, jeden einzelnen Algorithmus neu zu schreiben. Für viele Teilschritte der automatisierten Handschriftenanalyse kann stattdessen bereits bestehende Software genutzt oder zumindest angepasst werden. Entsprechend wird diese Möglichkeit im Projekt eCodicology wahrgenommen. Hauptsächlich kommen zwei Softwares zum Einsatz, zum einen das Bildbearbeitungsprogramm ImageJ und zum anderen die Software Weka, die verschiedene Algorithmen zum maschinellen Lernen bereitstellt. Daneben wird auch der KIT Data Manager verwendet, eine Datenbank- und Verwaltungssoftware, die die Bilddateien und die dazu gespeicherten Metadaten bereithält.
Der Quellcode der Softwares ist unter freien Lizenzen (GNU General Public License und Apache-License 2.0) veröffentlicht worden, sodass die in den Softwares enthaltenen Algorithmen von jedem weiterverwendet und verändert werden dürfen. Auf dieser Grundlage wurden die Softwares für eCodicology angepasst und um zusätzliche Algorithmen erweitert, damit sie optimal auf die Untersuchung der mittelalterlichen Handschriften zugeschnitten sind.
Probleme bei der Digitalisierung
Zur Durchführung der Handschriftenanalyse selbst wird zunächst einmal eine größere Anzahl digitalisierter Handschriften benötigt. Dazu werden die Handschriften üblicherweise gescannt und als Bilddatei gespeichert, damit an der digitalisierten Version möglichst viele Eigenschaften des Originals sichtbar bleiben, wie zum Beispiel im Text enthaltene Bilder, oder die Farbe und Gestaltung der Anfangsbuchstaben auf einer Seite.
Bei diesem Vorgang der Image-Digitalisierung, also der Digitalisierung von analogem Material als Bilddatei, treten jedoch einige Probleme auf, wie zum Beispiel das Bildrauschen: Einzelne Bildpixel werden in einer Farbe oder Helligkeit dargestellt, die sich auffallend von der benachbarter Pixel unterscheidet, wodurch die Qualität des digitalen Bildes beeinträchtigt wird.
Weiterhin werden die Farben in einer Bilddatei selten genauso wiedergegeben, wie sie am Original wahrgenommen werden. Dies kann mehrere Ursachen haben, beispielsweise eine falsche Farbkalibrierung der Bildschirme, unterschiedliche Voreinstellungen der zur Digitalisierung verwendeten Geräte oder die Licht- und Farbverhältnisse der Umgebung. Somit unterscheidet sich nicht nur die Abbildung vom Original, sondern auch jede Abbildung von einer weiteren Abbildung desselben Originals.
Vorverarbeitung der Digitalisate
Der erste Schritt der Handschriftenuntersuchung in eCodicology ist also die gründliche Vorverarbeitung der digitalisierten Handschriften. In diesem Schritt werden durch ein Bildbearbeitungsprogramm Störungen in den einzelnen Bilddateien beseitigt, soweit es die technischen Möglichkeiten erlauben.
Dazu gehört zunächst die Angleichung der Farben in den Bilddateien an das Original. Zu diesem Zweck wird bereits beim Scannen eine Leiste mit Standardfarben neben die Handschriftenseiten gelegt.
Anhand dieser Farbleiste lässt sich dann ermitteln, inwieweit die Farben in der Abbildung von den Standardfarben abweichen. Sobald diese Abweichung bekannt ist, können die Farbwerte in der Bilddatei wieder an die Standardfarben angeglichen werden. Dazu wurde für eCodicology ein Algorithmus verwendet, der die Farbwerte für Rot, Grün und Blau in der Abbildung ermittelt und mit den Original-Farbwerten der Farbleiste verrechnet. Somit ergeben sich Koeffizienten, mithilfe derer für den Farbwert jedes einzelnen Bildpixels ein alternativer Wert errechnet werden kann, welcher dem Farbwert der originalen Handschriftenseite möglichst nahe kommt.
Zusammen mit der Farbleiste wurde beim Scannen auch eine Messleiste zu den Handschriftenseiten gelegt. Denn die Größe eines Pixels ist nicht fest, sondern hängt von der Auflösung ab, in der die Bilddatei gespeichert wird. Mithilfe dieser Messleiste kann der Bezug zwischen der Größe der Bilddatei und der Größe des Originals hergestellt werden. Dazu wird durch die Software abgezählt, wie viele Bildpixel einem Zentimeter auf der Messleiste entsprechen. So können später Messungen, die an der Bilddatei durchgeführt wurden, korrekt von Pixeln in Zentimeter umgerechnet werden.
Außerdem wird das Bildrauschen so weit wie möglich reduziert, im Idealfall sogar ganz entfernt.
Danach werden die Dateien in einer niedrigen Auflösung gespeichert, denn je kleiner die Dateien sind, umso weniger Zeit benötigt die Software für die Auswertung der einzelnen Bilder.
Nach diesen Zwischenschritten sind die digitalisierten Handschriftenseiten so weit vereinheitlicht, dass Unterschiede zwischen den Seiten nicht mehr auf Ungenauigkeiten im Digitalisierungsprozess zurückzuführen sind. Diese Einheitlichkeit ist die notwendige Voraussetzung für folgenden Schritt der Handschriftenanalyse.

Segmentierung und Klassifizierung
In diesem Arbeitsschritt wird die Unterscheidung zusammengehöriger Bildregionen von ihrer Umgebung und die Zuordnung zu bestimmten Seitenbereichen vorgenommen. Im Projekt eCodicology sind das die bereits genannten vier Bereiche Seitengröße, beschriebene Fläche, Zeilenhöhe, und, sofern vorhanden, Größe der Bilder.
Dazu ist für einen Algorithmus zunächst das Problem zu lösen, wie sich die einzelnen Seiteneinheiten überhaupt voneinander unterscheiden. Was für den Menschen auf einen Blick zu erkennen ist, muss für den Computer erst anhand möglichst aussagekräftiger Kriterien explizit festgelegt werden.
Die Abgrenzung verschiedener Bildbereiche, die Segmentierung, wird üblicherweise durchgeführt, indem Unterschiede in der Pixelverteilung gesucht werden. Dazu werden für benachbarte Pixel Faktoren wie Farbe und Helligkeit verglichen. Pixel mit ähnlichen Werten werden zu einer Einheit zusammengefasst.

{kind=link}
Für die Klassifizierung wiederum wird bei eCodicology ein Verfahren namens Random Forest Classifier verwendet. Dazu wird der Algorithmus zunächst an einer Auswahl von Bilddateien trainiert. In diesem Trainingsprozess werden zufällig (random) Folgen von Abfragen, sogenannte Entscheidungsbäume, generiert. Mithilfe der Abfragen werden Merkmale ermittelt, die die segmentierten Bildbereiche voneinander unterscheiden. Von diesen Entscheidungsbäumen wird wiederum ein ganzer „Wald“ (Forest) gebildet. Danach kann der Klassifikator auf die Gesamtheit der digitalisierten Handschriftenseiten angewendet werden.
Dabei wird jeder einzelne Entscheidungsbaum für jede zuvor segmentierte Bildeinheit neu durchlaufen und ordnet diese einem der vier vorab festgelegten Bildbereiche zu. Am Ende erfolgt dann durch die Gewichtung dieser einzelnen Zuordnungen die endgültige Zuteilung der betrachteten Bildeinheiten zu einer der vier genannten Größen: den Textbereich, die Zeile als Untereinheit des Textbereiches, den Bildbereich oder den Seitenhintergrund.
Dann wird in einem nächsten Schritt berechnet, wie viele Pixel in jedem dieser Bereiche sind. Auf dieser Einteilung basierend, werden die Maße in Zentimetern ermittelt.
Um die Korrektheit des Verfahrens zu gewährleisten, wird der Algorithmus zunächst an Beispielbildern getestet, ehe man ihn auf alle übrigen anwendet.
Was geschieht mit den gewonnenen Daten?
Am Ende dieses Prozesses erfolgt die Bereitstellung der Maße, damit diese weiter verwertet werden können. Dazu werden die Maße zu der Datei hinzugefügt, in der bei der Digitalisierung schon die übrigen Metadaten zur jeweiligen Handschrift abgespeichert wurden.
Diese gesammelten Daten werden statistisch ausgewertet, also zusammenfasst und unter unterschiedlichen Gesichtspunkten einander gegenüber gestellt, und können dann nach den Methoden der quantitativen Kodikologie auf Zusammenhänge untersucht werden.
Chandna, Swati; Tonne, Danah; Jejkal, Thomas et al., Software workflow for the automatic tagging of medieval manuscript images (SWATI), in: Proc. SPIE 9402, Document Recognition and Retrieval XXII, 940206, 08. Februar 2015, online: http://dx.doi.org/10.1117/12.2076124 [28.04.2016].
DFG-Praxisregeln »Digitalisierung«, 02/2013, online: http://www.dfg.de/formulare/12_151/12_151_de.pdf [28.04.2016].
Liaw, Andy; Wiener, Matthew, Classification and Regression by randomForest, in: R News 2(3), 2002, S. 18-22, online: http://www.bios.unc.edu/~dzeng/BIOS740/randomforest.pdf [28.04.2016].